
在使用KubeBuilder开发Kubernetes Operator的时候,会出现资源过期问题。本文解释成因及解决方案。
问题
端午节我在寝室给一个项目闷头写Operator的时候。设计了这样的一个用于创建Pod一次性执行特定任务的CRD。大概过程是,CR创建时,应该按照Spec的内容构建一个Pod,然后在Pod进入Failed阶段就重试,重试多次后标记任务失败,Complete就标记为任务完成。伪代码如下:
func (r *TrainTaskReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
reqLogger := log.FromContext(ctx).WithValues("TrainTask", req.NamespacedName, "rand", rand.Float64())
// 获取当前的TrainTask的定义
var trainTask anylearnv1.TrainTask
if err := r.Get(ctx, req.NamespacedName, &trainTask); err != nil {
// reqLogger.Info("unable to fetch TrainTask")
return ctrl.Result{}, client.IgnoreNotFound(err)
}
if trainTask.Status.State == "Finished" || trainTask.Status.State == "Failed" {
// 已经结束的任务没有必要再启动
// reqLogger.Info("TrainTask is over", "state", trainTask.Status.State)
return ctrl.Result{}, nil
}
// 查看当前TrainTask定义的Pod是否存在
var taskPods v1.PodList
if err := r.List(ctx, &taskPods, client.InNamespace(req.Namespace), client.MatchingFields{trainTaskOwnerKey: req.Name}); err != nil {
reqLogger.Error(err, "unable to list child Pods")
return ctrl.Result{}, err
}
createNewPod := false
statusNeedUpdate := false
// 判断当前是否需要创建一个新的容器来运行任务
// 判读状态是否需要更新,之所以要先判断再更新而不是直接更新是为了避免过多的对APIServer的写入
{
// 检查是否需要创建新Pod以及更新状态
createNewPod = true
statusNeedUpdate = true
}
if statusNeedUpdate {
// 这个地方会出Conflict
if err := r.Status().Update(ctx, &trainTask); err != nil {
return ctrl.Result{}, err
}
}
if createNewPod {
// 创建新容器,删除老容器...
}
return ctrl.Result{}, nil
}在更新状态的步骤,可能会出现Error:
Operation cannot be fulfilled on [Resource Kind\Resource Name]: the object has been modified; please apply your changes to the latest version and try again
成因
下面来解释一下原因以及解决方案:
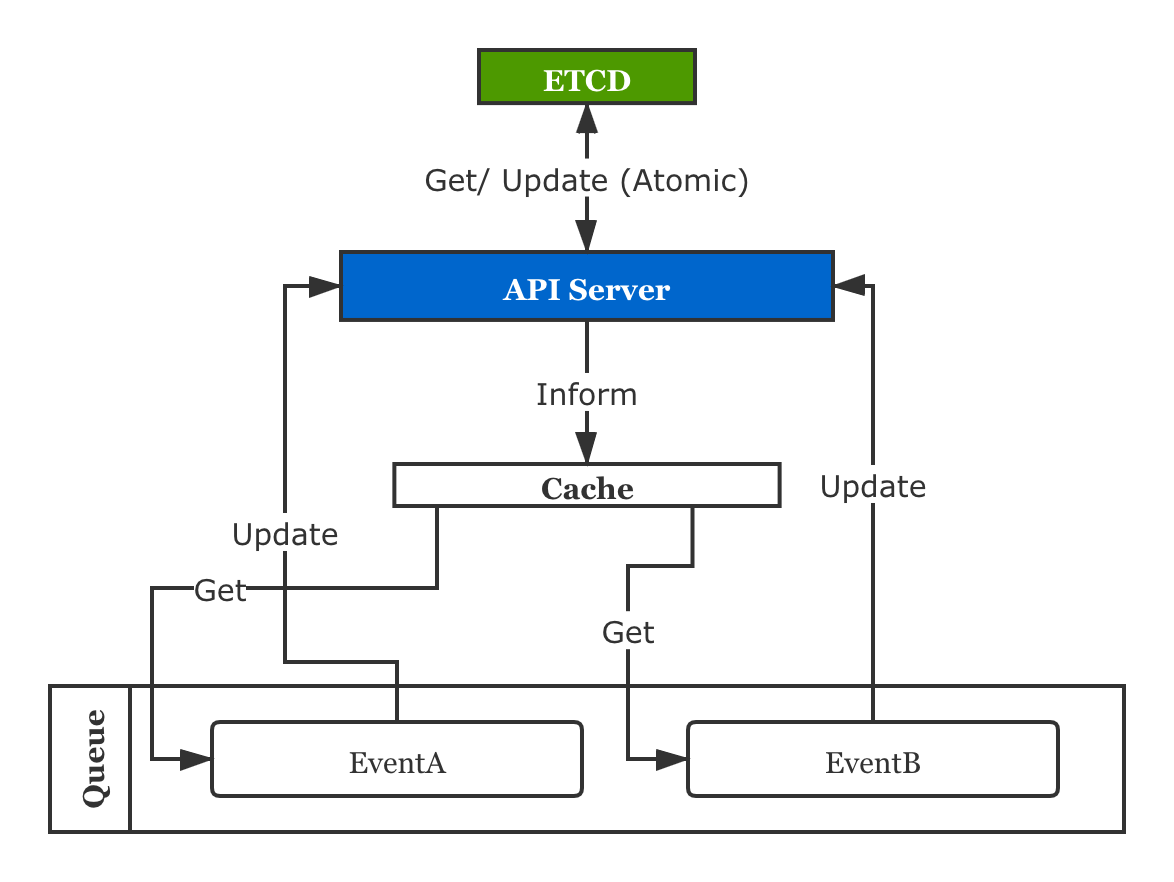
ResourceVersion会在Resource的任意字段被修改时更新,包括Metadata,Spec和Status。 Kubebuilder内部的实现中,读是用APIReader走缓存的,写是直接走APIServer写ETCD的。其中从APIServer到ETCD的步骤是原子操作,但是从ETCD到Cache这整个链路并不是原子的。
两个连续的Event可能会出现,A向APIServer提交Update或者Patch修改了资源对象,ETCD确认了更新(这里是原子的),但是还没来得及将新的资源inform给缓存,B紧随其后从缓存中读到的是一个旧版本,再向ETCD更新时,ETCD会拒绝这次更新。
资源Conflict在Kubernetes中是很常见的错误,原因就是Kubernetes为了提高吞吐,在全局很多地方都采用乐观锁的设计。
解决方案
解决方案也很简单,在Update时,如果发现是ConflictError就使用Requeue: True重新执行这个Event,或者在Conflict发生时使用Kubernetes提供的retry.RetryOnConflict。但是,在retry时,注意请根据新Get到的资源版本重新计算状态,而不是Get了一个新的资源对象然后直接拿之前基于旧资源对象算出的状态去Update。个人觉得既然都要基于新的资源对象重新计算状态了,干脆Requeue是最好的。我比较推荐的Reconcile写法如下:
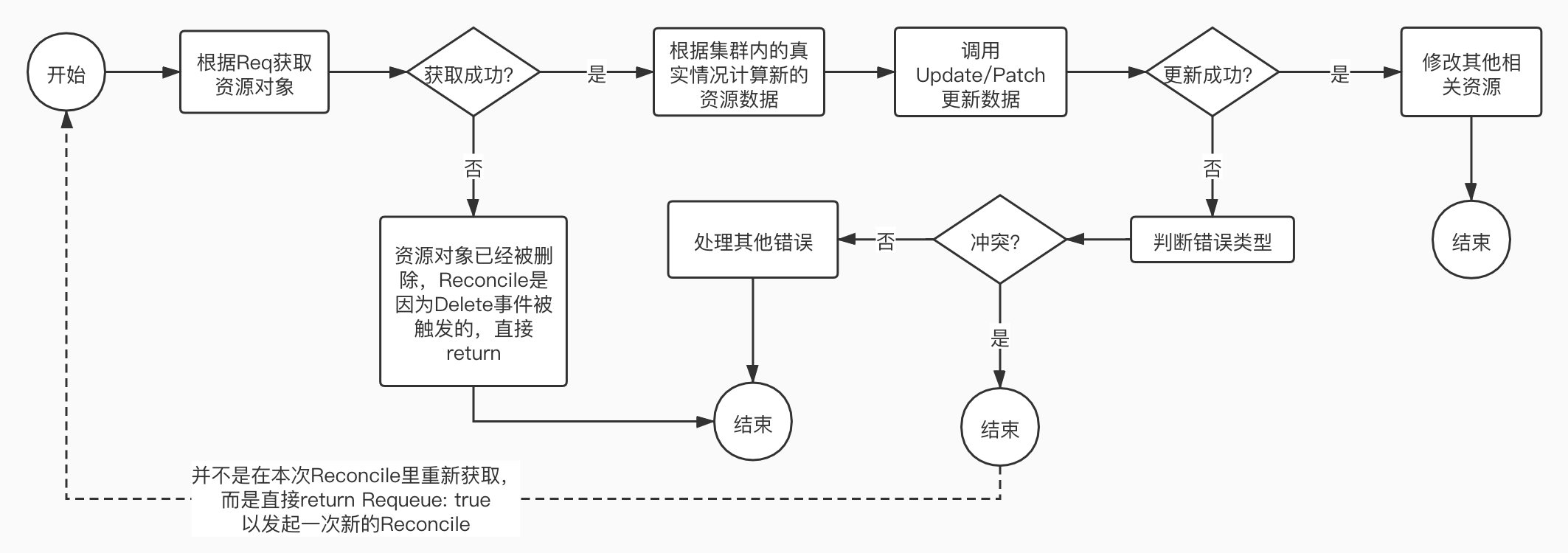
if statusNeedUpdate {
// 在获取并更新状态前什么都不要做,如果更新失败就说明手里拿到的已经是一个老的版本了,就重新排队
if err := r.Status().Update(ctx, &trainTask); err != nil {
if apierrors.IsConflict(err) {
return ctrl.Result{Requeue: true}, nil
} else {
reqLogger.Error(err, "unexpected error when update status")
return ctrl.Result{}, err
}
}
}
我参考了其他Operator的写法,ElasticSearch的Operator在出现Conflict的时候,也采用了直接Requeue的做法:
err = updateStatus(params, ready, desired)
if err != nil && apierrors.IsConflict(err) {
params.Logger.V(1).Info(
"Conflict while updating status",
"namespace", params.Beat.Namespace,
"beat_name", params.Beat.Name)
return results.WithResult(reconcile.Result{Requeue: true})
}
err = r.updateStatus(ctx, es, state)
if err != nil {
if apierrors.IsConflict(err) {
log.V(1).Info("Conflict while updating status", "namespace", es.Namespace, "es_name", es.Name)
return reconcile.Result{Requeue: true}, nil
}
k8s.EmitErrorEvent(r.recorder, err, &es, events.EventReconciliationError, "Reconciliation error: %v", err)
}
return results.WithError(err).Aggregate()
相关评论